
Caio Velasco
caiocvelasco at gmail dot com
My Website & Data Science Portfolio
Senior Data & Analytics Engineer with 6+ years of experience building modern data platforms, analytics products, trusted data models, reporting layers, and predictive solutions that support better decision-making.
I have worked with international clients across the US, UK, Brazil, and Europe, contributing to projects spanning data ingestion, platform migrations, warehouse transformation, dimensional modeling, data quality, governance, and self-service analytics. My core stack includes dbt, Snowflake, Databricks, Redshift, SQL, Python, and AWS, with experience across insurance, aviation, sports, e-commerce, and IoT.
My work sits at the intersection of analytics engineering, data engineering, and applied data science. Alongside building analytics-ready data foundations, I have developed churn and reactivation propensity models for a Brazilian football club loyalty program and contributed to econometric research for a World Bank project.
I am a Mechanical Engineer from UFRJ, where I graduated cum laude, and hold a Master’s in Economics, Data Science, and Public Policy from UCLA, completed with full scholarships from the Lemann Foundation and the Meyer and Renee Luskin family.
Throughout my academic and professional journey, I have received scholarships and recognition from institutions including UCLA, Yale University, the Lemann Foundation, the General Electric Foundation, Goldman Sachs, and The Club of Rome.
Earlier in life, I participated in national physics and mathematics olympiads and competed (and still do) in semi-professional football and handball championships.
Data & Analytics Engineering
1. Data Ingestion & Integration
Focus: reliable data movement, schema control, and cost-efficient storage
2. Transformation & Data Modeling
Focus: analytical correctness, business logic, and scalable modeling
- Transformation: dbt-Snowflake - S3 (Parquet) → Snowflake External Tables
- How to migrate an ETL to dbt
- Fundamentals of Snowflake Architecture, Stored Procedures, Streams, and Tasks
3. Change Data Capture & Slowly Changing Dimensions
Focus: historical correctness and temporal consistency
4. Data Quality, Observability & Reliability
Focus: trust, monitoring, and CI/CD-driven quality guarantees
- Data Observability for Raw Stripe Data in S3 with CI/CD
- Lead Quality Process: S3 (Parquet, CSVs) → Postgres (Bronze / Silver / Gold)
5. Analytics & Machine Learning Enablement
Focus: ML-ready data, feature pipelines, and reproducibility
Applied Data Science & Machine Learning
Tech Stack: Python (Pandas, NumPy, Statsmodels, scikit-learn, CausalInference)
1. Causal Inference & Experimentation
Focus: estimating impact, not just predicting outcomes
- Causal Inference: Effect of a New Recommendation System
- Causal Inference: Effect of a Customer-Satisfaction Program
2. Applied Machine Learning & Predictive Modeling
Focus: translating data into actionable signals
3. Data Analysis & Modeling Foundations
Focus: analytical rigor, feature preparation, and reproducibility
- Data Cleaning: Preparing Categorical Data for Modeling
- Data Cleaning: Parsing Date and Time Zones for Modeling
Teaching, Mathematical Foundations & Statistical Thinking
Tech Stack: Quarto, Markdown, LaTeX, GitHub Pages
Foundations of Data Science, Statistics & Causal Machine Learning
Focus: rigorous mathematical foundations, intuition-building, and applied causal reasoning
See all projects below!
Data & Analytics Engineering
1. Data Ingestion & Integration
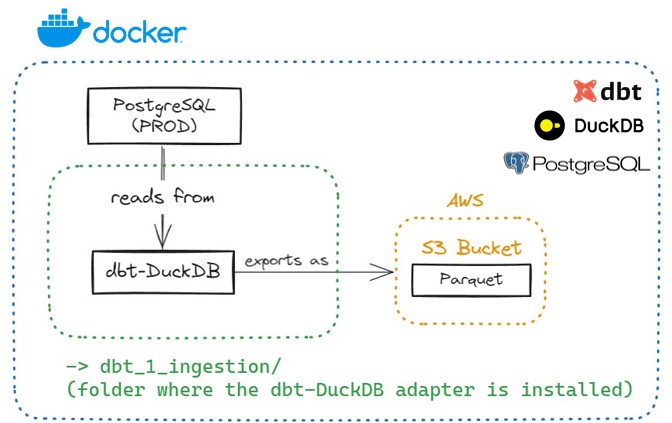
Ingestion: dbt-DuckDB — Postgres → AWS S3 (Parquet)
This project uses a Dockerized environment to extract data from Postgres (as if it were data in “Production”). Then, it converts the data into Parquet files, saving them into an AWS S3 Bucket. I used my AWS Free Tier account and implemented the dbt-DuckDB adapter to expand dbt’s core functionality (transformation) into an ingestion layer.
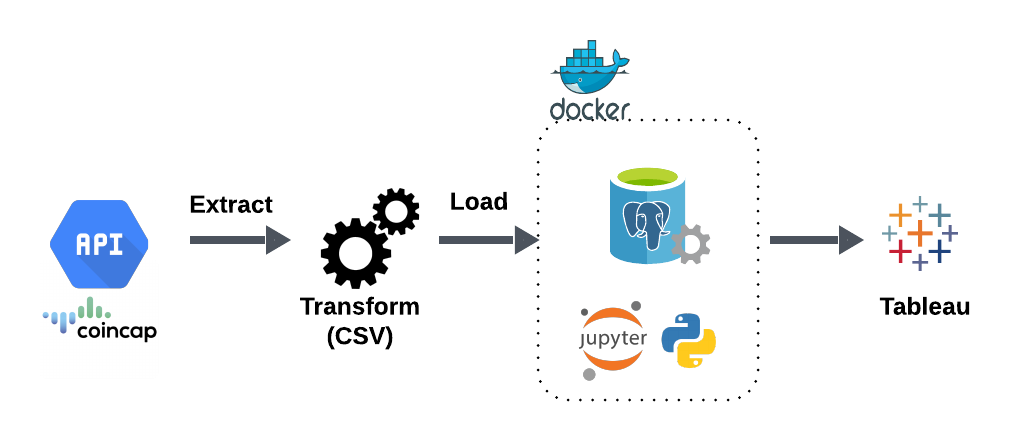
ETL Pipeline: Crypto API → Tableau (CSV)
This ETL pipeline uses Python functions to extract data from an external API and transform it into CSV files for downstream consumption by Tableau or other visualization tools. The project runs in a Dockerized environment with PostgreSQL and Jupyter Notebook for interactive exploration.
2. Transformation & Data Modeling
Transformation: dbt-Snowflake — S3 (Parquet) → Snowflake External Tables
This project extracts Parquet files stored in S3 using Snowflake External Tables. dbt performs transformations and materializes dimension and fact tables in the Silver layer, along with aggregated tables in the Gold schema, following the Medallion Architecture and Kimball Dimensional Modeling.
![]()
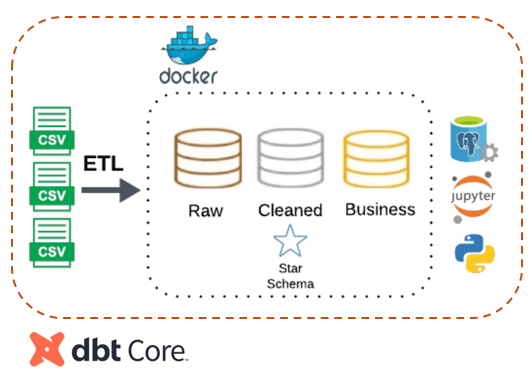
Migrating ETL (Medallion Architecture & Kimball Modeling) to dbt
This project expands a previous Python-based ETL to simulate a real-world migration to dbt. Data is extracted from multiple CSV files, and transformation and loading are performed in PostgreSQL via dbt, following Bronze, Silver, and Gold layers and a star schema design.
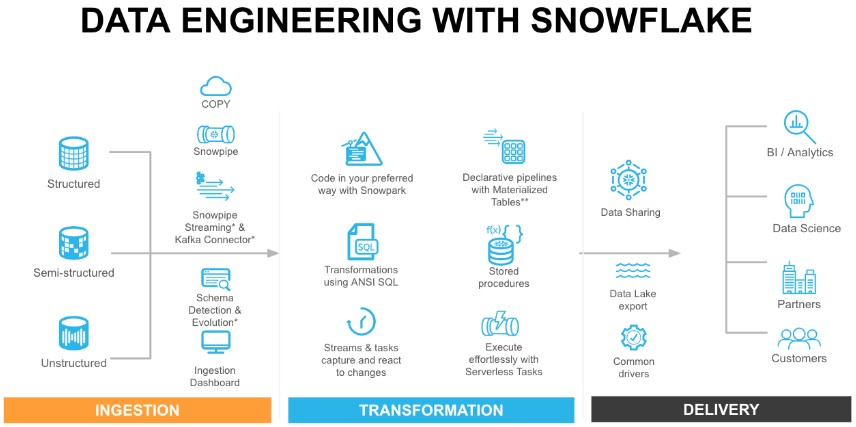
Fundamentals of Snowflake Architecture, Stored Procedures, Streams, and Tasks
This guide covers four essential pillars of Snowflake mastery:
- Snowflake Architecture & Performance Fundamentals
- Procedural SQL, Streams & Tasks
- AWS S3 Integration & Data Loading
- Orchestration & ELT Design
3. Change Data Capture & Slowly Changing Dimensions
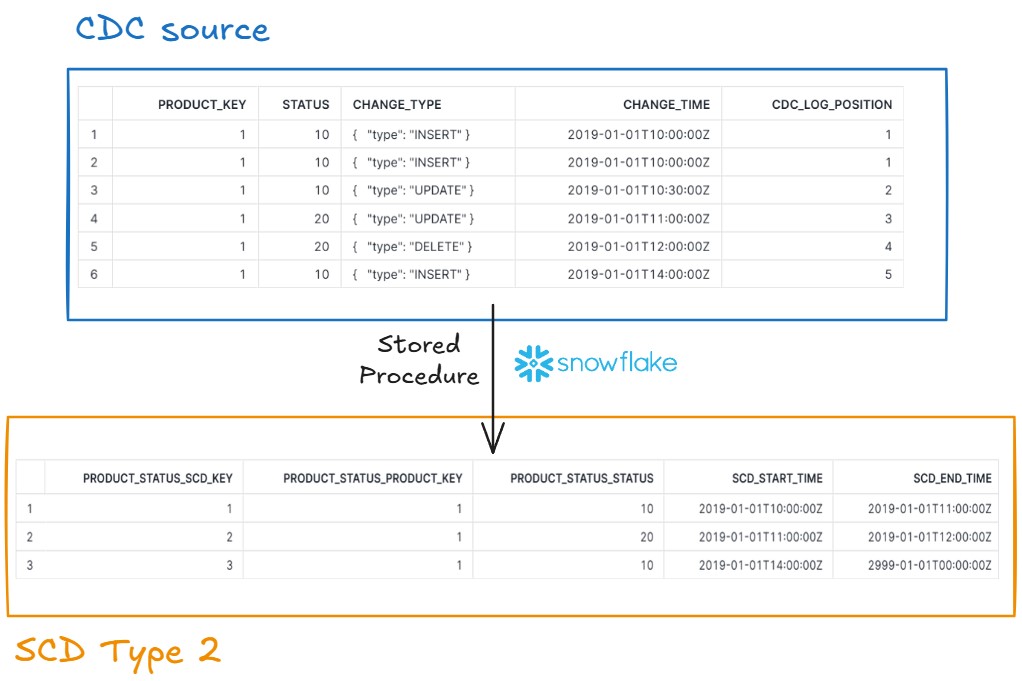
Implementing CDC with SCD Type 2 in Snowflake
This project implements a Slowly Changing Dimension (SCD) Type 2 to track historical changes in product status using a CDC stream as the source. The pipeline ensures ordered, deduplicated events, idempotency, and basic data quality checks via stored procedures.
4. Data Quality, Observability & Reliability
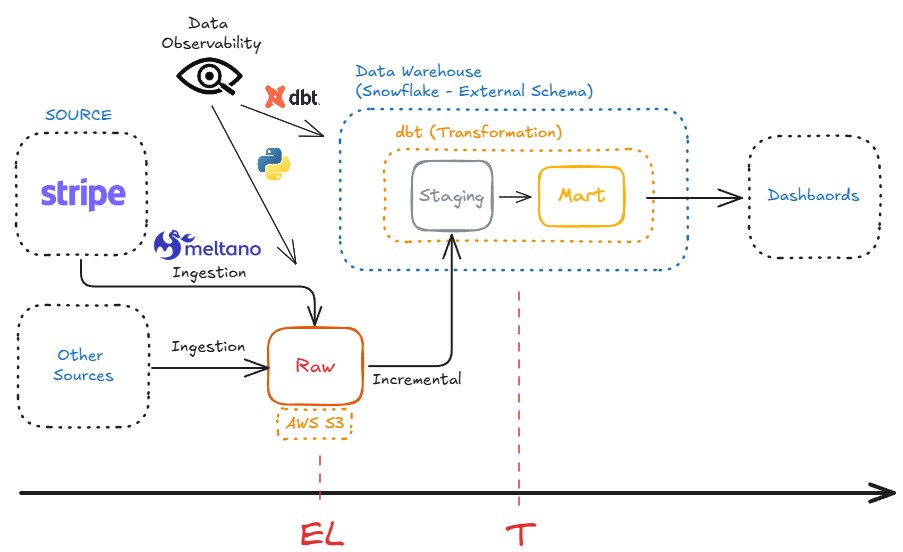
Data Observability for Raw Stripe Data in S3 with CI/CD
This project provides a lightweight observability layer for raw Stripe data ingested into S3 via Meltano. The goal is to validate the raw layer before downstream transformations.
Key features include:
- File presence and content validation
- Schema validation and early drift detection
- Single orchestration entrypoint
- Secure AWS integration via
boto3 - CI/CD support through GitHub Actions
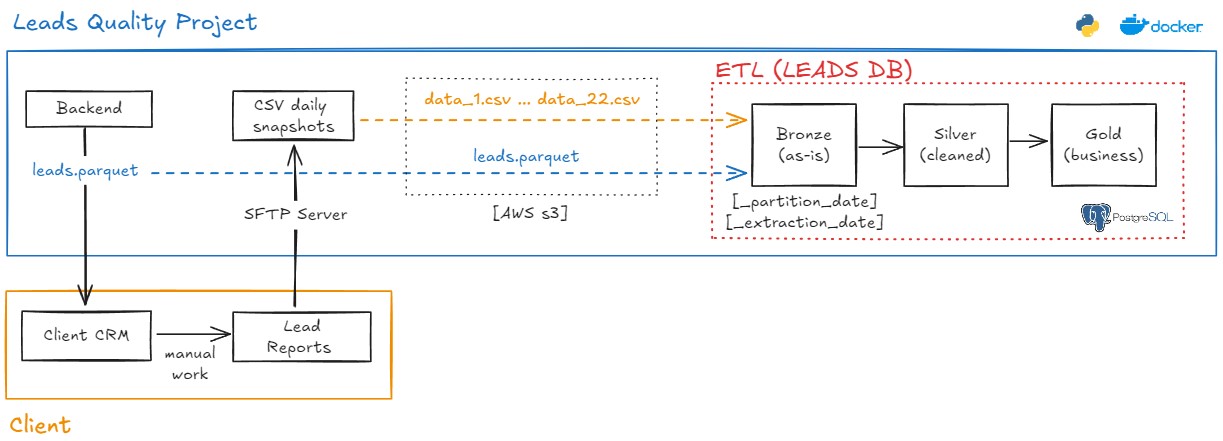
Lead Quality Process: S3 → Postgres (Bronze / Silver / Gold)
This project uses a Dockerized environment to extract Parquet and CSV data from S3 and load it into PostgreSQL, following the Medallion Architecture and object-oriented transformation design.
5. Analytics & Machine Learning Enablement
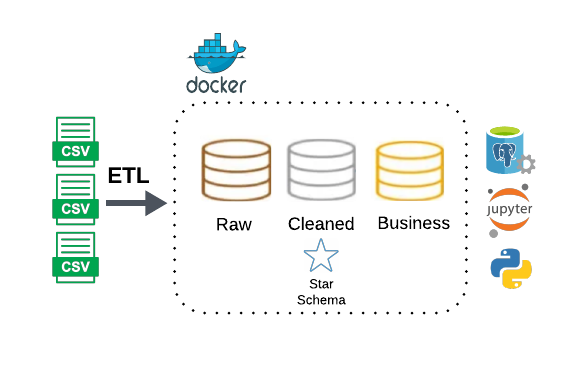
ETL for Machine Learning (Churn Prediction)
This project builds an end-to-end Python ETL pipeline designed for machine learning use cases. The pipeline runs in Docker, uses PostgreSQL and Jupyter Notebook, and follows the Medallion Architecture and Kimball star schema to produce ML-ready feature tables.
Applied Data Science & Machine Learning
1. Causal Inference & Experimentation
Causal Inference (Propensity Score Matching & Difference-in-Differences):
Measuring the Effect of a New Recommendation System on an E-Commerce Marketplace

Causal Inference (Difference-in-Differences):
Measuring the Effect of a New Customer-Satisfaction Program on an Airline Company

2. Data Analysis & Modeling Foundations
Focus: analytical rigor, feature preparation, and statistical best practices
Data Cleaning: Preparing Categorical Data for Modeling
When datasets are large, it can take forever for a Machine Learning model to make predictions. This project focuses on storing and encoding categorical data efficiently without changing dataset size.
Data Cleaning: Parsing Date and Time Zones for Modeling
Best practices for parsing, standardizing, and validating date, time, and time zone data prior to modeling.
Data Analysis & Inferential Statistics with Python

Advanced Mathematics, Statistics, and Machine Learning
I have a strong interest in teaching and in building clear bridges between mathematical foundations, statistical reasoning, and real-world data science practice. I care deeply about rigor, intuition, and the responsible use of quantitative methods in decision-making.
Foundations of Data Science & Causal Machine Learning: A Mathematical Journey
I’m developing a long-term open study book (and future course) focused on the mathematical and statistical foundations underlying Data Science, Econometrics, and Causal Machine Learning. The goal is to make advanced concepts accessible without sacrificing rigor, and to connect theory directly to modern ML and applied data problems.
The project is freely available online:
Foundations of Data Science & Causal Machine Learning – A Mathematical Journey